

یادگیری عمیق که زیرمجموعه یادگیری ماشین است، عملکردی شبیه به مغز انسان دارد اما به جای قرار گرفتن در بدن انسان، در یک ماشین جاسازی شده است. این الگوریتم از عملکرد مغز انسان الهام گرفته و بنابراین مجموعهای از الگوریتمهای شبکه عصبی است که سعی میکند عملکرد مغز انسان را تقلید کند و از تجربیات آن بیاموزد.
در این مقاله قصد داریم با نحوه عملکرد شبکه عصبی هوش مصنوعی (artificial neural networks) و نحوه عملکرد آن آشنا شویم. با ما همراه باشید.
شبکه عصبی در هوش مصنوعی چیست؟
شبکههای عصبی، که با نامهای شبکه عصبی مصنوعی (ANN) یا شبکههای عصبی شبیهسازی شده (SNN) نیز شناخته میشوند، زیرمجموعهای از یادگیری ماشین هستند و در قلب الگوریتمهای یادگیری عمیق قرار دارند. نام و ساختار آنها از مغز انسان الهام گرفته شده است و از روشی تقلید میکنند که نورونهای بیولوژیک به یکدیگر سیگنال میدهند.
شبکههای عصبی مصنوعی (ANN) از یک لایه گره تشکیل شدهاند که شامل یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی است. هر گره یا نورون مصنوعی به دیگری متصل میشود و دارای وزن و آستانه مرتبط است. اگر خروجی هر گره منفرد بالاتر از مقدار آستانه مشخص شده باشد، آن گره فعال میشود و داده ها را به لایه بعدی شبکه ارسال می کند. در غیر این صورت، هیچ دادهای به لایه بعدی شبکه منتقل نمیشود.
شبکه های عصبی برای یادگیری و بهبود دقت خود در طول زمان به دادههای آموزشی متکی هستند. اما زمانی که این الگوریتمهای یادگیری برای دقت بالا تنظیم شوند، ابزار قدرتمندی در علوم کامپیوتر و هوش مصنوعی هستند که به ما این امکان را میدهند تا دادهها را با سرعت بالا طبقهبندی و خوشهبندی کنیم. وظایف تشخیص گفتار یا تشخیص تصویر با این شبکهها چند دقیقه طول میکشد، در حالی که همان کار با شناسایی دستی توسط متخصصان انسانی میتواند ساعتها طول بکشد. یکی از شناخته شده ترین شبکه های عصبی، الگوریتم موتور جستجوی گوگل است.
اگر بخواهیم به بیان ساده توضیح دهیم که شبکههای عصبی در هوش مصنوعی چیست، باید بگوییم ANN مجموعهای از الگوریتمهایی است که سعی میکنند الگوها، روابط و اطلاعات را از دادهها از طریق فرآیندی که از مغز انسان/زیستشناسی الهام گرفته و مانند آن کار میکند، تشخیص دهد.
مولفهها و ساختار شبکه عصبی
لایه ورودی: این مفهوم همچنین به عنوان گرههای ورودی شناخته میشود، ورودی/اطلاعات دنیای بیرون برای یادگیری و نتیجهگیری در اختیار مدل قرار میگیرد. گرههای ورودی، اطلاعات را به لایه بعدی یعنی لایه پنهان منتقل می کنند.
لایه پنهان: لایه پنهان مجموعهای از نورونها است که در آن تمام محاسبات روی دادههای ورودی انجام میشود. در یک شبکه عصبی، تعداد زیادی لایه پنهان میتواند وجود داشته باشد. سادهترین شبکه از یک لایه پنهان تشکیل شده است.
لایه خروجی: لایه خروجی، همان طور که نام آن نشان میدهد، خروجی/نتیجه مدلی است که از تمامی محاسبات انجام شده به دست میآید. در لایه خروجی میتوان گرههای منفرد یا چندگانه وجود داشته باشد. اگر مشکل طبقهبندی باینری داشته باشیم، گره خروجی 1 است، اما در مورد طبقهبندی چند کلاسه، گرههای خروجی میتوانند بیش از 1 باشند.
پرسپترون و پرسپترون چندلایه
پرسپترون شکل ساده ای از شبکه عصبی است و از یک لایه تشکیل شده است که تمام محاسبات ریاضی در آن انجام میشود.
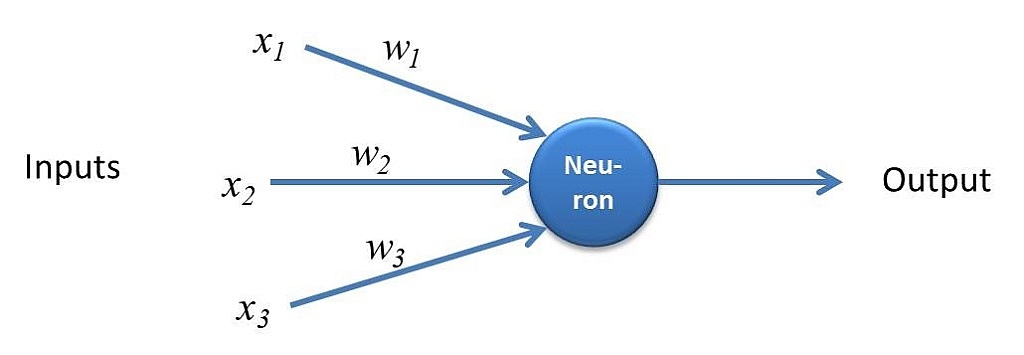
اما پرسپترون چند لایه – که به عنوان شبکه های عصبی مصنوعی نیز شناخته میشود – از بیش از یک ادراک تشکیل شده است که برای تشکیل یک شبکه عصبی چند لایه با هم گروهبندی میشوند.
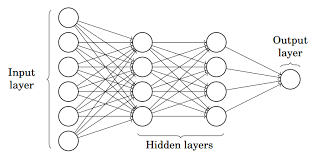
در تصویر بالا، شبکه عصبی مصنوعی از چهار لایه تشکیل شده است که به یکدیگر متصل هستند:
- یک لایه ورودی، با 6 گره ورودی
- لایه پنهان 1، با 4 گره پنهان / 4 پرسپترون
- لایه پنهان 2، با 4 گره پنهان
- لایه خروجی با 1 گره خروجی
شبکه های عصبی چگونه کار میکنند؟
هر گره جداگانه را به عنوان مدل رگرسیون خطی خود در نظر بگیرید که از دادههای ورودی، وزنها، یک سوگیری (یا آستانه) و یک خروجی تشکیل شده است. فرمول چیزی شبیه به این خواهد بود:
∑wixi + bias = w1x1 + w2x2 + w3x3 + bias
output = f(x) = 1 if ∑w1x1 + b>= 0; 0 if ∑w1x1 + b < 0
وقتی یک لایه ورودی تعیین شد، وزنها تخصیص داده میشود. این وزنها به تعیین اهمیت هر متغیر معین کمک میکنند و متغیرهای بزرگتر در مقایسه با سایر ورودیها به میزان قابل توجهی در خروجی نقش دارند. سپس تمام ورودیها در وزن مربوطه ضرب و سپس جمع میشوند. پس از آن، خروجی از طریق یک تابع فعالسازی عبور داده میشود که خروجی را تعیین میکند. اگر آن خروجی از یک آستانه معین فراتر رود، گره را “روشن” (یا فعال) میکند و دادهها را به لایه بعدی در شبکه ارسال میکند. این امر باعث میشود که خروجی یک گره به ورودی گره بعدی تبدیل شود. این فرآیند انتقال داده از یک لایه به لایه بعدی، این شبکه عصبی را به عنوان یک شبکه عصبی پیشخور تعریف می کند.
در ادامه تجزیه و بررسی خواهیم کرد که یک گره منفرد با استفاده از مقادیر باینری چگونه به نظر میرسد. بیایید با یک مثال این مفهوم را ملموس کنیم. برای مثال این سوال را مطرح کنیم که آیا باید به موجسواری بروید (بله: 1، خیر: 0). تصمیم برای رفتن یا نرفتن، نتیجه پیشبینی شده ما یا y-hat است. بیایید فرض کنیم که سه عامل بر تصمیمگیری شما برای رفتن به موجسواری تأثیر میگذارد:
- آیا میزان امواج خوب است؟ (بله: 1، خیر: 0)
- آیا صف موجسواران خالی است؟ (بله: 1، خیر: 0)
- آیا اخیراً حمله کوسه در آن منطقه رخ داده است؟ (بله: 0، خیر: 1)
حالا بیایید مواردی را فرض کنیم که ورودیهای زیر را به ما میدهد:
- X1 = 1، زیرا امواج در حال افزایش و بالا آمدن هستند
- X2 = 0، زیرا مردم بیرون در صف حضور دارند
- X3 = 1، زیرا حمله اخیر کوسه صورت نگرفته است
اکنون، برای تعیین اهمیت باید چند وزن تعیین کنیم. وزنهای بزرگتر نشان می دهد که متغیرهای خاص اهمیت بیشتری برای تصمیم یا نتیجه دارند.
- W1 = 5، از آنجایی که موجهای بزرگ معمولاً در اطراف ایجاد نمیشوند
- W2 = 2، چون به شلوغی عادت کردهاید
- W3 = 4، زیرا شما از کوسه میترسید
در نهایت، مقدار آستانه 3 را نیز در نظر میگیریم که به معنای مقدار بایاس 3 است. با تمام ورودیهای مختلف، میتوانیم مقادیر را به فرمول اضافه کنیم تا خروجی مورد نظر را به دست آوریم.
Y-hat = (1*5) + (0*2) + (1*4) – 3 = 6
اگر از ابتدای این بخش تابع فعالسازی استفاده کنیم، میتوانیم تعیین کنیم که خروجی این گره 1 باشد، زیرا 6 بزرگتر از 0 است. اما اگر وزنها یا آستانه را تنظیم کنیم، می توانیم به نتایج متفاوتی از مدل دست یابیم. وقتی یک تصمیم را مشاهده میکنیم، مانند مثال بالا، میتوانیم ببینیم که چگونه یک شبکه عصبی با توجه به خروجی تصمیمات یا لایههای قبلی میتواند تصمیمات پیچیدهتری بگیرد.
در مثال بالا، ما از پرسپترونها برای نشان دادن برخی از ریاضیات در اینجا استفاده کردیم، اما شبکههای عصبی از نورونهای سیگموئید استفاده میکنند که با داشتن مقادیری بین 0 و 1 متمایز میشوند. از آنجایی که شبکههای عصبی مشابه درختهای تصمیمگیری رفتار میکنند، سرازیر شدن دادهها از یک گره به یک گره دیگر، با توجه به داشتن مقادیر x بین 0 و 1، تأثیر هر تغییر معین یک متغیر را بر خروجی هر گره معین، و متعاقباً، خروجی شبکه عصبی را کاهش میدهد.
زمانی که درباره موارد استفاده کاربردیتر شبکههای عصبی، مانند تشخیص یا طبقه بندی تصویر، فکر می کنیم، از یادگیری نظارت شده یا مجموعه دادههای برچسبگذاریشده برای آموزش الگوریتم استفاده خواهیم کرد. همانطور که مدل را آموزش میدهیم، میخواهیم دقت آن را با استفاده از تابع هزینه (یا ضرر) ارزیابی کنیم. این موضوع معمولاً به عنوان خطای میانگین مربعات (MSE) نیز شناخته می شود. در معادله زیر،
- i معرف شاخص نمونه است،
- y-hat نتیجه پیش بینی شده است،
- y مقدار واقعی است،
- m تعداد نمونهها است.
تابع هزینه = 𝑀𝑆𝐸=1/2𝑚 ∑129_(𝑖=1)^𝑚▒(𝑦 ̂^((𝑖) )−𝑦^((𝑖) ) )^2
در نهایت، هدف این است که عملکرد هزینه خود را به حداقل برسانیم تا از صحت تناسب برای هر مشاهدهای اطمینان حاصل کنیم. همانطور که مدل، وزن و سوگیری خود را تنظیم میکند، از تابع هزینه و یادگیری تقویتی برای رسیدن به نقطه همگرایی یا حداقل محلی استفاده میکند. فرآیندی که در آن الگوریتم، وزنهای خود را تنظیم میکند از طریق گرادیان نزولی اتفاق میافتد که به مدل اجازه میدهد جهت کاهش خطاها (یا به حداقل رساندن تابع هزینه) را تعیین کند. با هر مثال آموزشی، پارامترهای مدل تنظیم میشوند تا به تدریج در حداقل همگرا شوند.
بیشتر شبکههای عصبی عمیق پیشخور هستند، به این معنی که فقط در یک جهت و تنها از ورودی به خروجی جریان دارند. با این حال، می توانید مدل خود را از طریق روش پس انتشار نیز آموزش دهید. یعنی از خروجی به ورودی در جهت مخالف حرکت کنید. پس انتشار به ما اجازه میدهد تا خطای مربوط به هر نورون را محاسبه و نسبت دهیم. این روش همچنین به ما امکان می دهد پارامترهای مدل(های) را به طور مناسب تنظیم و برازش کنیم.
انواع شبکه های عصبی
شبکه های عصبی را می توان به انواع مختلفی طبقه بندی کرد که برای اهداف گوناگونی استفاده میشوند. فهرست زیر، لیست کاملی از انواع شبکههای عصبی نیست، اما رایجترین انواع شبکههای عصبی را معرفی میکند که کاربردهای زیادی دارند:
- پرسپترون (perceptron): قدیمی ترین شبکه عصبی است که توسط فرانک روزنبلات (Frank Rosenblatt) در سال 1958 ایجاد شد.
- شبکههای عصبی پیشخور یا پرسپترونهای چندلایه (MLPs): نوعی از شبکههای عصبی است که در این مقاله و در قسمت قبل عمدتاً روی آن تمرکز کردهایم. این شبکهها از یک لایه ورودی، یک لایه یا لایه های پنهان و یک لایه خروجی تشکیل شدهاند. اگرچه این شبکههای عصبی معمولاً به عنوان MLP نیز شناخته میشوند، توجه به این نکته مهم است که آنها در واقع از نورونهای سیگموئید تشکیل شدهاند، نه پرسپترونها، زیرا اکثر مشکلات دنیای واقعی غیرخطی هستند. معمولاً دادهها برای آموزش به این مدلها وارد میشوند و این مدلها پایه و اساس بینایی کامپیوتر، پردازش زبان طبیعی و سایر شبکههای عصبی هستند.
- شبکههای عصبی کانولوشنال (CNN): این شبکهها شبیه شبکههای پیشخور هستند، اما معمولاً برای تشخیص تصویر، تشخیص الگو و/یا بینایی کامپیوتری استفاده میشوند. این شبکهها از اصول جبر خطی، به ویژه ضرب ماتریس، برای شناسایی الگوهای درون یک تصویر استفاده میکنند.
- شبکههای عصبی بازگشتی (RNN): این شبکهها با حلقههای بازخوردشان شناسایی میشوند. الگوریتمهای یادگیری شبکههای عصبی بازگشتی در درجه اول هنگام استفاده از دادههای سری زمانی برای پیشبینی نتایج آتی، مانند پیشبینی بازار سهام یا پیشبینی فروش، استفاده میشوند.
مقایسه شبکههای عصبی و یادگیری عمیق
واژههای یادگیری عمیق و شبکههای عصبی معمولاً به جای یکدیگر استفاده میشوند که میتواند گیجکننده باشد. اما نکته مهم این است که مفهوم “عمیق” در یادگیری عمیق فقط به عمق لایهها در یک شبکه عصبی اشاره دارد. یک شبکه عصبی که از بیش از سه لایه تشکیل شده است – و شامل ورودیها و خروجیها میشود – میتواند یک الگوریتم یادگیری عمیق در نظر گرفته شود. یک شبکه عصبی که فقط دو یا سه لایه دارد، فقط یک شبکه عصبی اولیه است.
و در پایان این که…
در این مطلب شبکههای عصبی هوش مصنوعی پرداختیم. شبکههای عصبی هوش مصنوعی، که معمولاً به سادگی شبکههای عصبی یا ANN نامیده میشوند، سیستمهای محاسباتی هستند و از شبکههای عصبی بیولوژیک الهام گرفته شدهاند.
اگر به حوزه هوش مصنوعی علاقهمند هستید یا در این حوزه فعال هستید و یا دوست دارید که از محصولات هوش مصنوعی استفاده کنید، شرکت هوش مصنوعی آویر این امکان را فراهم ساخته تا به جدیدترین محصولات هوش مصنوعی و تکنولوژی روز دسترسی داشته باشید.
![[object Object]](/_next/image?url=https%3A%2F%2Fblog.avir.co.com%2Fwp-content%2Fuploads%2F2024%2F03%2F%D8%AF%D8%A7%D8%AF%D9%87-%DA%A9%D8%A7%D9%88%DB%8C.webp%3Fkey%3D0.10213374540314568&w=3840&q=75)

![[object Object]](/_next/image?url=https%3A%2F%2Fblog.avir.co.com%2Fwp-content%2Fuploads%2F2024%2F03%2F%D9%87%D9%88%D8%B4-%D9%85%D8%B5%D9%86%D9%88%D8%B9%DB%8C-%D8%A7%D8%AE%D9%84%D8%A7%D9%82%DB%8C.webp%3Fkey%3D0.9528569653160812&w=3840&q=75)
![[object Object]](/_next/image?url=https%3A%2F%2Fblog.avir.co.com%2Fwp-content%2Fuploads%2F2024%2F02%2F%D9%87%D9%88%D8%B4-%D9%85%D8%B5%D9%86%D9%88%D8%B9%DB%8C-%D9%85%D9%88%D9%84%D8%AF-%DA%86%DB%8C%D8%B3%D8%AA.webp%3Fkey%3D0.8773008628590888&w=3840&q=75)
![[object Object]](/_next/image?url=https%3A%2F%2Fblog.avir.co.com%2Fwp-content%2Fuploads%2F2024%2F02%2F%D9%87%D9%88%D8%B4-%D9%85%D8%B5%D9%86%D9%88%D8%B9%DB%8C-%D9%BE%D8%A7%DB%8C%D8%AF%D8%A7%D8%B1.webp%3Fkey%3D0.3693480854657598&w=3840&q=75)